2.2.1 Характеристика використаних даних
Обчислювальні експерименти (ОЕ) мали на меті встановити швидкісні та прогностичні властивості нових програмних засобів у порівнянні з існуючими. При обчисленнях у тестових задачах було використано як штучно створені дані, так і реальні медичні дані. Точки навчальної та контрольної вибірок випадково згенерованих задач формувалися як рівномірно розподілені точки на одиничному кубі в просторі ознак Rn. Після цього точки першого класу зсувалися по першій координаті на величину σ, а точки другого класу – по першій координаті на величину (-1-σ). При σ›0 навчальна та контрольна вибірки є лінійно розділимими, а при σ‹0 вони лінійно нерозділимі. Далі виконувався поворот (лінійне перетворення) простору так, щоб розділяюча гіперплощина залежала від багатьох координат простору Rn.
Реальні дані містили інформацію про експресію генів хворих на рак пацієнтів (143 спостереження за 60483 показниками), отримані з The Cancer Genome Atlas (TCGA). З цих даних за допомогою спрощеного методу ранжування ознак Новоселової Н. А. [5] було виокремлено 23 найбільш інформативні показники стосовно прогнозу вітального статусу пацієнтів, у яких діагностовано гліобластому. Метою залучення таких даних було встановити переваги/недоліки застосування різних програмних засобів на такому тестовому масиві.
У якості методів, з якими відбувалося порівняння обрано методи інтегровані в бібліотеку scikit–learn, а саме – “Linear SVC”, “NuSVC”, “Ada Boost”. Два з останніх є нелінійними класифікаторами і долучені до порівняння для отримання додаткової інформації про те, які переваги мають різні методи на різних задачах.
2.2.2 Методика проведення обчислювальних експериментів
Згідно з рекомендаціями з прогностичного моделювання [25, 30] до наборів даних попередньо було застосовано стандартизацію (Z-score normalization). Для побудови моделі та її перевірки дані були розділені випадковим чином на два набори– «тренувальний» (80%) та «тестовий» (20%). Для досягнення відтворюваності результатів ОЕ ці набори було збережено в окремих файлах.
Хронометраж фіксував лише час побудови моделі (завантаження даних та тестування моделі не враховувались). Для кожного набору даних збережено протокол та діаграму recall–precision [24, 158], яка дозволяє більш детально оцінити якість роботи методів класифікації.
2.2.3 Результати обчислювальних експериментів
Основні результати ОЕ наведені у табл. 2. Зупинимось на аналізі окремих результатів з цієї таблиці.
Для набору даних «UnBalance_200_1000_1000_0.001.txt» встановлено, що створений програмний засіб NonSmoothSVC має невеликі переваги у якості лінійного класифікатора (див. Рис. 2), але (як і в більшості інших випадків) поступається у швидкості побудови моделі. Якісні переваги програмного засобу NonSmoothSVC полягають не тільки у більшому показнику точності 0.904 (цей параметр характеризує частку правильно розпізнаних випадків; коли він дорівнює 1, це означає, що всі точки були класифіковані правильно), але й у тому, що помилково класифіковані спостереження розташовані ближче до розділяючої гіперплощини ніж у інших методів.
Таблиця 2
Порівняння придатності до застосування, точності та швидкості роботи лінійний та нелінійних класифікаторів на штучно згенерованих та реальних наборах даних

Рисунок 2 – Якість роботи класифікаторів на наборі даних «UnBalance_200_1000_1000_0.001.txt»
На реальних даних (набір «vital_status_data_23.txt») також виявлені якісні переваги програмного засобу NonSmoothSVC над іншими. По-перше – за допомогою нелінійного методу «NuSVC» (налаштування параметрів не проводилось) отримати результат на цьому наборі даних не вдалося. По-друге і програмний засіб NonSmoothSVC, і Linear SVC продемонстрували однакову максимальну точність – ‘1’, але розташування гіперплощини для NonSmoothSVC має перевагу (див. Рис. 3). Вона полягає у тому, що проміжок між двома класами є більшим у програмного засобу NonSmoothSVC.
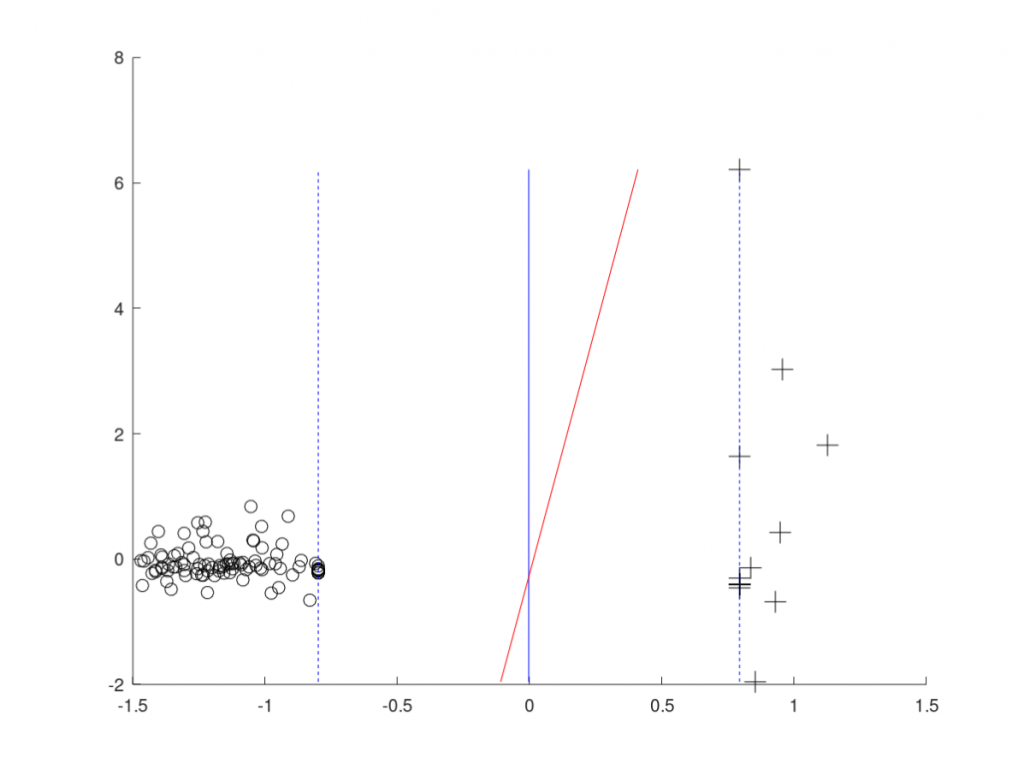
Рисунок 3 – Візуалізація проекцій гіперплощин отриманих методами «Non Smooth SVC» (вертикальна лінія у центрі) та «Linear SVC» (лінія під нахилом у центрі) та спостережень (вітальний статус пацієнта з діагнозом гліобластома: ‘o’ – негативний; ‘+’ – позитивний) на наборі даних «vital_status_data_23.txt»
Висновки.
Обчислювальні експерименти показали, що на деяких наборах даних програмний засіб NonSmoothSVC має якісні переваги над іншими долученими до порівняння методами, але у швидкості (інколи суттєво) поступається їм.